From Transaction Labels to Customer Understanding: The Third Layer of Slope Transformer
This is the second post in a series on how Slope's data-science team is using AI to improve the underwriting of small businesses. The previous post was about how we use an AI-driven research loop to produce better features for our traditional underwriting ML model. This post goes one layer down the stack, to what feeds the features, that is the the labels. Whether a wire is revenue or a loan, whether a credit-card payment is working capital or debt service, whether a $40M money-market sweep is real economic activity or overnight cash management: every feature we just described, every model we train, and every credit decision we make on bank data sits on top of answers to questions like these. And as I'll show, text-only labeling has a structural ceiling when it comes to answering them well.
A brief recap of Slope Transformer
Bank-transaction labeling is the foundation of bank-data-based cashflow underwriting. Every feature our ML model uses, every credit memo our team writes, every repayment-capacity estimate we make starts with an answer to one question: who is this transaction with, and what kind of economic relationship does it represent? Get that wrong at the bottom of the stack and everything above it bends.
We built Slope Transformer because we needed something the off-the-shelf options couldn't give us: concise, deterministic counterparty labels (plus a category and subcategory for each transaction) at production latency, trained on Slope's own corpus of transaction descriptions. The counterparty is the most important of the three outputs. It is the atomic unit of meaning in a bank statement, and it is what every higher layer of our pipeline hangs off.
Slope Transformer solved the per-transaction classification problem well. It's still the first thing that sees any bank data flowing into our underwriting pipeline. But for underwriting a business (especially a small business financed largely off its cashflow) per-transaction labels are only the starting point. Labeling a wire "revenue" is only useful if you actually know it is revenue, and not, say, a loan disbursement wearing revenue's text. The string alone can't tell you.
The three layers we've converged on
Over the last year we've ended up with a three-layer architecture for bank transaction understanding. Each layer answers a question the previous layer can't.
- Layer 1 — Slope Transformer. Input: one transaction string. Output: counterparty, plus a category and subcategory. Question answered: who is this transaction with, and what kind of thing is it? Counterparty is the most reliable of the three outputs and the anchor everything above depends on.
- Layer 2 — CashflowAnalysis. Input: all of a customer's transactions, grouped by counterparty from Layer 1. Output: a structured, holder-based view of the business's cashflow. Each significant counterparty is assigned to one of a small set of economic roles (recurring revenue, COGS, payroll, installment lenders, line of credit, fixed expenses, personal spending, and a couple of deliberately-flagged buckets for items that deserve human attention), and each gets a set of statistics describing how it behaves: how regular the payments are, how they move with revenue, how big they are relative to everything else. Out of that comes a reconciled monthly income statement, a debt structure view, and a picture of the customer's cashflow graph. Question answered: what role does this counterparty play in the business, and what do its patterns tell us?
- Layer 3 — AI context review (the new layer). Input: everything from Layers 1 and 2 plus a structured review protocol. Output: a single JSON object containing two different kinds of content: label corrections that flow back into the traditional ML model, and severity-tagged findings and action items that flow out to our risk team or to the customer. Question answered: what does this transaction actually do in the cashflow, and what do we still not know about this business?
Layer 3 is the subject of this post. It is not a new model; it is a structured reasoning agent that reads the output of the first two layers the same way a human reviewer does when reading a cashflow dashboard, and produces the kind of synthesis an underwriter needs to make a decision.
Why text-only labels have a structural ceiling in cashflow underwriting
Three reasons, each load-bearing.
Banks throw away information before the labeler sees it. Wire memos are truncated. ACH descriptions use codes. Descriptions that arrive in our pipeline are already lossy compressions of the economic reality that produced them. Even a perfect text-only model is working from incomplete data.
Counterparty names obscure economic roles. This is the important one. A law firm holds escrow for a lender, and the wire memo reads like a law firm, but the money is a loan disbursement. A professional employer organization handles payroll, and the name looks like any other B2B service, but the payments are wages. A credit card funds inventory and the counterparty is Capital One, but the economic expense is cost of goods sold. The name you see tells you about the entity moving the money. It often says very little about what the transaction does in the business's cashflow.
Economic meaning is relational. Whether a given transaction should be classified as revenue, financing, or an internal transfer depends on what else the business is doing — on whether this counterparty shows up repeatedly, on whether there's a matching outflow in another holder, on whether the amount moves with revenue or against it. These structural questions don't live in any one transaction's string. They live in the web of transactions the business has with the world.
In casual payments analytics these are edge cases. In small-business cashflow underwriting they are the core of the problem. Whether a $1.4M wire is revenue or an SBA loan is the difference between two very different credit decisions.
What "context-based reasoning" actually means
Layer 3 doesn't look at one transaction at a time. It looks at the whole Layer-2 picture and asks structural questions that are computable from the statistics already there:
- Does the counterparty's entity type match the economic role? A material inflow from an individual's personal name, sitting in a revenue bucket for a business that normally sells to corporate customers, is worth a second look. The typical B2B pattern is corporate payers, and a one-off personal name warrants asking why.
- Does the timing pattern fit the label? A "fixed expense" that fires on the same day each month with near-zero amount variability is probably a loan or a rent, not a vendor bill; a counterparty labeled as a "supplier" that shows strong correlation with revenue at a particular time offset is probably tied to the sales cycle, not independent overhead.
- Is there a matching counterpart? A material one-time inflow that has no plausible matching outflow elsewhere (in COGS, in refunds, in a lender's disbursement stream) is suspect. A bidirectional counterparty whose fee rate is within card-processor norms is likely a card processor; one that's well outside the norm is likely something else.
- Does the in/out ratio give it away? Bidirectional same-day pairs with near-zero net are a sweep, not an economic activity. Counterparties with outflows far exceeding inflows but labeled as financing are lines of credit being drawn down.
These are the questions a human reviewer asks. What's new is that we've put an AI agent in the reviewer's seat. Layer 3 is an LLM-driven agent that follows a structured review protocol, navigating the cashflow object one holder at a time rather than swallowing it whole, running Python when a number needs to be checked (a correlation, a gap distribution, a cross-reference between holders), and reaching for web search when a counterparty name is ambiguous and the samples don't resolve it. A lot of counterparty verification comes down to "is this entity a lender, a supplier, a PEO, a processor?" and a lot of that answer lives on the open web, on the entity's product page or regulatory filings. The agent treats each counterparty and each anomaly as its own small investigation, gathers what it needs, and emits a specific recommendation, either a label change with a reason, or a specific question for a human to answer.
The rest of this post is four cases where this matters, drawn from several different customers. All are anonymized; only household names (Amazon, Capital One, American Express, JPMorgan) remain.
Case 1 — the "revenue" that was an SBA loan
The customer sells on Amazon and a handful of smaller marketplaces. On one day in late December 2025 a single wire of roughly $1.4M hit their bank account. The memo read, verbatim and truncated: WT … TRUIST BANK /ORG=[individual person's name] PA DBA. Slope Transformer, doing exactly what it's trained to do on the string, classified the inflow as Revenue / B2B Revenue. At the per-transaction level, that's a defensible guess: a large wire from a named payer, coded the way vendor payments to an LLC typically look.
Layer 2, having all of the customer's transactions, saw what Layer 1 couldn't. This wire was a singleton, one transaction, one date, no prior history from this counterparty. At $1.4M, it was over half of the customer's all-time inflow. Layer 2's rules for a material non-recurring inflow that isn't an internal transfer place it automatically into suspicious_material_inflow, a holder whose whole purpose is to surface items like this for a closer look, regardless of what Layer 1 labeled them. So by the time the data reached our agent, the classification question was already teed up: Layer 2 had said "this is material, this is not recurring, this is not internal; somebody needs to figure out what it actually is."
So the agent went to work. It pulled the counterparty's samples, looked up the wire memo pattern against what it knows about professional-services legal structures, and checked for any matching outflows elsewhere in the cashflow object. Each piece of its reasoning mapped to a specific signal Layer 2 had already produced:
- The counterparty is an individual, not a business. The payer's name is one person's full name followed by PA DBA, Professional Association doing business as, a legal structure common to law firms. For this customer's business type, an Amazon seller whose revenue is normally booked against marketplace payouts and corporate B2B customers, a material wire from an individual's personal name is out-of-pattern and worth scrutinizing.
- The routing is an escrow signature. TRUIST BANK / ORG = [individual] PA DBA is the memo pattern you see when a law firm moves money from its IOLTA or escrow account on behalf of the actual originator. When the agent web-searched the PA DBA format and cross-referenced a few similar wire strings in other customers' data, the shape was consistent: the bank and the "Org" on the wire are the intermediary, not the economic source of the funds.
- No matching trail. A real B2B revenue relationship of this size leaves a trail of smaller invoices, prior payments, a sales-cycle pattern. The agent checked the rest of the customer's recurring-revenue holder and the 12 months of prior history for anything from the same payer. There was nothing. Just a singleton wire.
- Cashflow reconciliation gets worse, not better, if this is revenue. The customer's self-reported annual revenue and their observed deposit volume already had a gap; the agent ran the reconciliation both ways and confirmed that treating this wire as revenue widened the gap, not narrowed it. A real new revenue source would do the opposite.
Layer 3's output captured all of this as a set of structured edits to the customer's review: the wire stays in suspicious_material_inflow (Layer 2 was right to put it there), but its Slope Transformer category gets corrected from Revenue / B2B Revenue to Financing Activities / Bank Loan, a severity-critical finding is logged, and a customer_action_item of type clarify_inflow is emitted: "Confirm the source of this wire. Our analysis suggests it is a loan disbursement routed through a law firm's escrow account, not B2B revenue."
The risk team took that action item to the customer. The answer came back: yes, an SBA loan, disbursed through the law firm handling the closing. The law firm was acting as escrow, exactly as Layer 3 had inferred from the structural signals.
This is a single case, but it is representative of why the new layer matters. Without it, this customer's apparent revenue was materially overstated, their debt load was materially understated, and every downstream underwriting metric (gross margin, debt-to-revenue, forecasted repayment capacity) was pointed in the wrong direction. Layer 1 gave the honest answer the string allowed. Layer 2 surfaced the statistics that made the truth knowable. Layer 3 did the reasoning and produced the specific, actionable output that let a human close the loop.
Case 2 — credit cards that are COGS, not debt service
This case shows up in different forms across a lot of our Amazon sellers, and it's the cleanest example of why revenue correlation is so powerful as a signal. The setup: a business that sells on Amazon has large monthly outflows to Capital One and American Express. Capital One in the $350K–$880K range per month, Amex in the $50K–$470K range. A text-only labeler reads "credit card payment" and puts these into the fixed-expenses or financing-expenses neighborhood. Either bucket is wrong, and either mistake distorts the picture: treated as fixed expense, the customer looks like they have bizarre overhead; treated as debt service, they look dangerously over-leveraged.
Layer 2 computed two numbers that reframed the whole story: revenue correlation with lag. For Capital One, card outflows correlated with Amazon revenue at r = 0.73, with the card payment arriving one month after the revenue. For Amex, it was r = 0.56 at two months after. In both cases the card outflow is lagging the revenue.
The left panel shows the alignment directly: when Amazon revenue rises (blue), the card payments rise a month or two later (orange and red). The right panel is the same story quantitatively, correlation at different time offsets, with peaks at +1 and +2 months.
Here the agent's job is the economic interpretation, the thing that's hard to state without actually thinking about what the business does. Reading the correlation pattern plus the card-issuer counterparties plus the Amazon revenue stream, the agent recognized the signature of an Amazon seller's working-capital cycle. The seller uses the credit card to float inventory purchases during a period, swipes that don't appear in bank data at all, because they happen at a supplier's terminal. The inventory ships to Amazon; Amazon sells it and pays the seller out a few weeks later; the seller then uses that revenue to pay down the card balance. What we see in the bank data, the outflow to Capital One, is the payoff event, which naturally lags the Amazon inflow by the credit card's billing cycle.
The card is a working-capital float. The underlying economic transaction is a purchase of inventory. The correct holder is COGS. It's not debt service because the card is being paid off in full each cycle, not carried. It's not a general fixed expense because the amounts rise and fall with revenue, not on a flat schedule. And it's not a line of credit in the accounting sense either because there's no persistent balance to report. The agent cross-checked each of those alternatives against the data before settling on COGS.
When Layer 3 made this move, the financial picture of the customer reorganized. COGS went from roughly $2M under the text-only view to roughly $6.7M under the context-aware view, the card spending moved into the right bucket. Gross profit dropped, yes, but it is now correct gross profit, at a gross margin that matches what Amazon FBA sellers actually earn. Debt-to-revenue collapsed into a healthy range because the cards stopped being double-counted as debt service. These aren't accounting preferences. They are the difference between looking at an over-leveraged customer with thin margins and looking at a normal Amazon seller with reasonable cashflow.
Case 3 — the "collection agency" that was a payroll provider
A different customer, a multi-channel ecommerce retailer. In their data, Layer 1 saw a fresh $220K/year ACH stream appear in early 2026, with the counterparty name [redacted] Services Collection Agency, a perfectly reasonable name for a B2B services firm. Slope Transformer categorized it as Professional Services / Other Professional Services. That's where the trouble starts: on the strength of that label, Layer 2 places it in fixed_expenses, where Slope-Transformer-labeled operational-services spend lands by default. As overhead, $220K/year is a big line item.
The tell wasn't in the label; it was in the cadence. Layer 2's statistics on this counterparty showed a flat near-monthly rhythm with low amount variability and low gap variability, the exact signature of a payroll processor, not a professional-services relationship. And Paychex was still running on the same customer at roughly the same cadence, providing a ready comparator pattern.
So the agent went to the web. Searching the counterparty name surfaced the company's own product pages: a Michigan-based Professional Employer Organization (a PEO) that handles payroll, benefits, and HR compliance for its client companies. The giveaway sitting inside the legal name, once you know what to look for, is the phrase Collection Agency: some PEOs are legally structured as collection agencies because their operating model involves collecting payroll funds from client companies and remitting them as wages, taxes, and benefits. It sounds like debt collection from the outside; it's payroll plumbing on the inside. With that identification in hand, the label correction wrote itself: the agent moved this counterparty from fixed_expenses to payroll, re-categorizing the Slope Transformer label from Professional Services / Other Professional Services to Employee Expenses / Payroll. The accompanying finding noted the stream alongside the still-active Paychex, useful context for anyone reading the review and for the model consuming the corrected holder totals downstream.
Case 4 — the $40M that didn't happen
Same retailer. Across the 12-month window, we saw ~$40M of outflows to JPMorgan U.S. Government Money Market Fund, spread across 103 transactions at very uniform amounts (amount CV ≈ 0.01, payments are essentially identical each time). Slope Transformer correctly labeled each outflow as Investing Expenses / Stock Brokerage Outflow, a reasonable per-transaction read of the text. Because Investing Expenses is a non-operational category, Layer 2's rules route the whole stream into agent_review: 103 outflows, $40M total, waiting for a human to explain what they are.
The corresponding inflow side, the redemptions when the money comes back from the fund, didn't land cleanly in any holder at all. Those inflows drifted into the unexplained residual. In this customer's reconciliation, unexplained_inflow_12m ran to over $40M, which is why inflow_explained_pct sat at only 16%. Layer 2 was capturing the two sides of the same sweep separately, and without an obvious counterparty match, it couldn't pair them. On paper, this customer had tens of millions of dollars of flagged investing outflows and tens of millions of unexplained inflows.
The agent recognized this as a sweep the way a human reviewer would, by checking each piece of the signature against the data. A quick Python check confirmed the amount uniformity (amount_cv ≈ 0.01, essentially the same payment over and over, unlike any discretionary investment pattern). A web search on the fund name surfaced what JPMorgan's U.S. Government Money Market Fund actually is: a product specifically designed to be used as an automatic-sweep vehicle for bank deposit accounts. And a residual check against the reconciliation object showed that the outflow total approximately matched the customer's unexplained inflow total, two halves of the same round-trip, captured separately by Layer 2 because the counterparty identifiers didn't line up. That combination of fund identity + flat amounts + outflow-matches-unexplained-inflow is the fingerprint of automatic overnight treasury management, not discretionary investing. The correction is to exclude both sides from the income statement entirely. These are not operating expenses, not investments the business chose to make, and not real economic activity in the underwriting sense. They are bank-software plumbing. The finding Layer 3 emits is informational: no adjustment to credit judgment, just an enormous amount of noise removed and the customer's reconciliation jumping from 16% explained to something much closer to complete.
The output: corrections and questions
The examples above share a structure. Each one produces two kinds of deliverable: a label correction that updates the customer's computed financials, and a narrative or a question that goes to a human.
This is not a happy accident; it is built into the schema Layer 3 emits. Here is a trimmed version of the contract:
Two different consumers read this output. The traditional ML model reads corrected_income_statement.adjustments and uses the corrected holder totals as inputs to features, exactly the kind of features I walked through in the previous post. The risk team, and sometimes the customer themselves, read the customer_action_items and the severity-tagged findings as a prioritized list of open questions and flagged observations about the customer.
This dual output is the point of Layer 3. It is not just a label-fixer. It is a structured reviewer: the computer does the part that's tedious and consistent (apply structural checks, propose corrections with reasoning), and the human does the part that requires judgment (call the customer, escalate the critical finding, close the loop). Every review we run leaves the ML model a little cleaner and leaves the risk team with a concrete, prioritized set of things to ask about.
Why this matters: closing the feedback loop
The four cases above illustrate Layer 3 at work on individual customers. The compounding value shows up when you zoom out.

For a single customer, the difference between text-only labels and context-aware labels is the difference between two substantively different credit pictures. Across a portfolio of thousands of customers, each with their own messy labeling edge cases, it's the difference between a slightly inaccurate model and an accurate one.
And more subtly: Layer 3's corrections flow upstream as well as downstream. Every adjustment is a labeled training example for the system — proof that, on this transaction stream, the correct classification was X even though the text suggested Y. Over time that stream of corrections is what will let us teach the full system, Slope Transformer and the reasoning layer together, to anticipate these patterns. And every feature we build on top of the CashflowAnalysis view, the features from the previous post, is only as sharp as the holder totals that feed it. Cleaner holders mean sharper features.
Labels feed features. Features feed decisions. Getting labels right in cashflow underwriting is load-bearing for everything downstream.
A personal note
It's hard to overstate how lucky I feel to be working on data science for small-business underwriting at this particular moment. The problems haven't gotten any easier and cashflow underwriting for small businesses is still the hard, messy, idiosyncratic work it's always been, but the tools available to attack them have changed fundamentally.
Slope Transformer was our team's first pass at closing the gap between what a bank statement says and what a business is actually doing. The CashflowAnalysis layer gave us a vocabulary for describing the relationships in a customer's cashflow graph. Layer 3, the reasoning layer this post is about, is what finally lets us put the two together and produce the kind of synthesis a human underwriter does in their head. None of the individual pieces are novel. What's novel is that we can now combine them at scale.
I don't think AI is going to solve underwriting. I think the opposite, actually: underwriting is one of those domains where the institutional knowledge of a team that's been making credit decisions for years is the moat, and no general-purpose model can replicate that. But I do think the tools are finally good enough that a small team with good judgment can point them at a serious problem and make progress that used to take much longer. That is what I've been trying to do here.
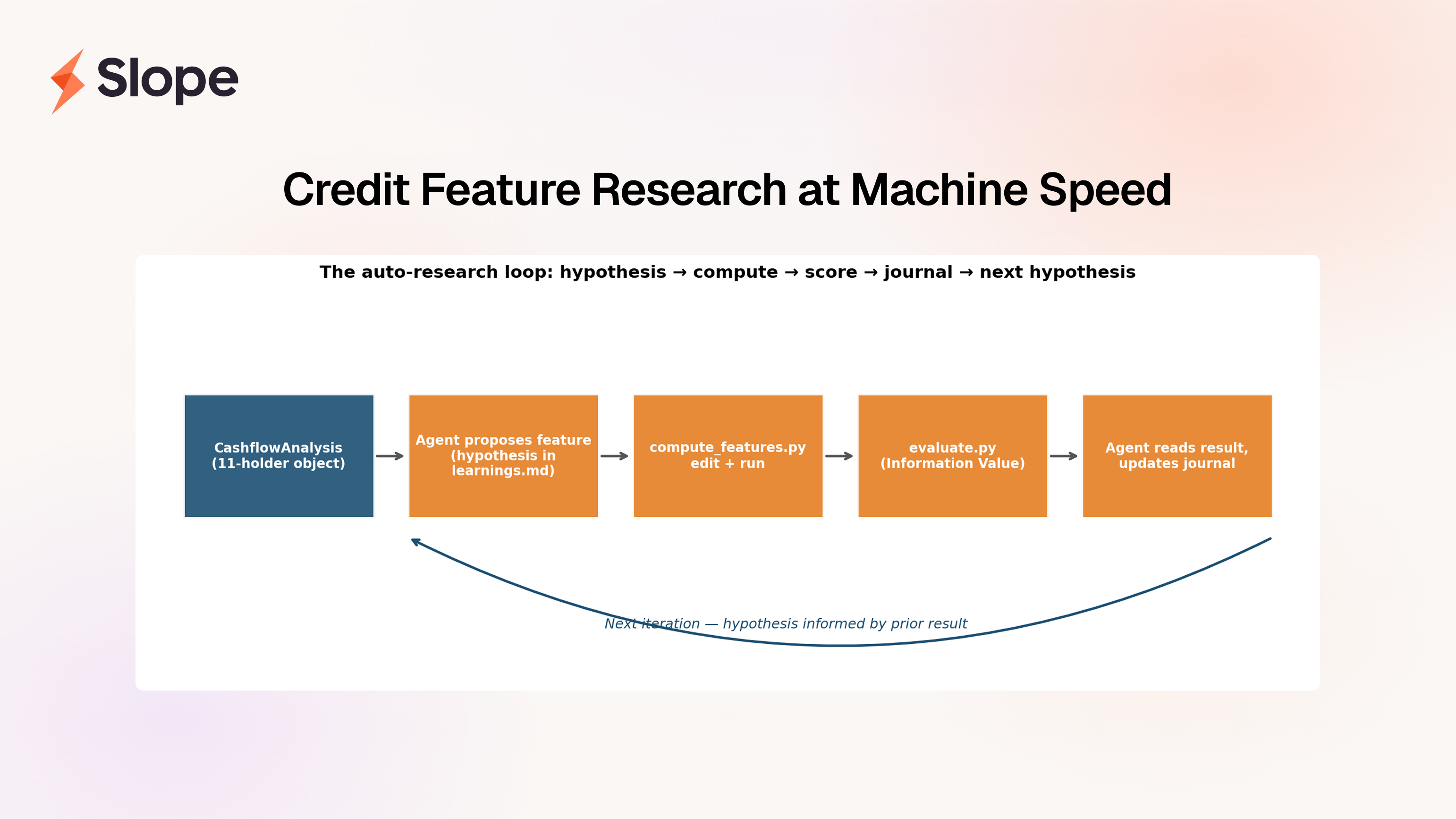
The previous post showed what we do on top of this: once the CashflowAnalysis holders can be trusted — once we know the "revenue" bucket really is revenue and the "COGS" bucket really is COGS — we can send an AI agent hunting through that structured view for credit features, dozens of them, each grounded in first-principles economic reasoning, at a cadence no small DS team could match by hand. Taken together, the two pieces are my answer to what the 2026-era DS toolkit looks like for small-business cashflow underwriting: cleaner labels at the bottom of the stack, sharper features in the middle, better credit decisions at the top.
— Jason Huang, CFA, Data Science at Slope